
How Deeply Deceptive? Dealing with the Deepfake.
 Suddenly, the realistic but concocted moving images known as “deep fakes” are very much in the news.
Suddenly, the realistic but concocted moving images known as “deep fakes” are very much in the news.
Those are versions of existing footage that has been jerryrigged to look very like the originals, but to convey something different, often with great plausibility.
Examples of the intrusion of “deep fakes” into daily life seem to be everywhere. Facebook recently declined to delete a doctored video of Nancy Pelosi, the speaker of the U.S. House of Representatives, that included footage slowed down or distorted to make her sound drunk or incoherent.
The President of her country publicized it in a tweet, and the President’s legal henchman, Rudy Giuliani, pushed the fake news further out into the Believ-o-Sphere.
Should we all shudder at the thought that manipulated images, both still and moving, as well as faked audio, are being pumped out around the globe, and are liable someday soon to undermine whole systems of goverment and the security of populations, as well as individual reputations and safety?
Will AI-generated “synthetic media” usher in a new era of who-knows-what-hell?
The technology is moving fast. One new software product, for example, allows users to add, edit, or delete segments of a video simply by inserting words from a transcript. A user runs the software, and specifies alterations via the transcript; then, the software creates altered images that reflect the written changes.
Not seamlessly but, again, increasingly plausibly.
The developers of that ingenious code — researchers from Stanford University, Max Planck Institute for Informatics, Princeton University, and Adobe Research — tout it as a way to reduce the need to re-shoot scenes when actors make mistakes, or when a script needs to be changed after shooting.
The likelihood is very high, of course, that such tools will be used maliciously — in election fraud, disinformation campaigns, media manipulation, the rise of authoritarian rule… In porn, of course — particularly the reputation-ruining variety.
Such uses are already common, although clumsily engineered, as yet.
It seems axiomatic that “deep fakes” will have a huge impact on moving-image archivists and archives. How certain will anyone be, in the future, that moving images have not come to them in an altered state? Complicating matters is that, in recent decades, films and their like are frequently highly manipulated by their original makers. When archiving a donated film, who will know what might have been done to it, surreptitiously?
And, to complicate matters even more, presumably altered moving images will be collected, too.
 Fakes will certainly require careful management, says John Tariot (left), who runs Film Video Digital, a commercial archive. In his work, he preserves motion-picture film for a national clientele of archives and film and TV production professionals. Increasingly, that means looking to the future: to developing digital strategies for preserving the integrity of motion-picture archives.
Fakes will certainly require careful management, says John Tariot (left), who runs Film Video Digital, a commercial archive. In his work, he preserves motion-picture film for a national clientele of archives and film and TV production professionals. Increasingly, that means looking to the future: to developing digital strategies for preserving the integrity of motion-picture archives.
Tariot’s history includes a key role in the advent of online stock footage. He has designed databases for NBC News, National Geographic, Paramount Pictures, CNN, and others organizations. And he also serves on the advisory committees of Peter Gabriel’s human-rights archive WITNESS (where concern is high about the possibility that authoritarian regimes will fake images of, for example, peacably protesting citizens) and the broadcast-industry bible POST Magazine.
Among Tariot’s current focuses is the looming impact of artificial intelligence on motion-picture archiving. He believes that archives will play an key role as “choke-points” in the emergence of the deepfakes era — that they will be charged with the role of verifying and authenticating whether moving images are “real” or not.
Tariot led a session about deep fakes at the 2018 annual conference of the Association of Moving Image Archivists, held in Portland, Oregon, and other meetings, and is planning another session at AMIA’s 2019 conference in Baltimore in November. On his company’s website, he has created an extensive online library of articles about the deep-fakes phenomenon.
He spoke to Moving Image Archive News about the subject — about the scope and nature of the issue, and about what the challenges are for archives and archivists. And, about what solutions are emerging.
“There are a lot of unique issues, challenges, and opportunities for archives and archivists,” he says. “We don’t have a lot of time to respond to it, so the information flow needs to get going.
“Archivists have to keep track of a lot of issues. Deepfakes or synthetic media in the motion-picture archives haven’t been around that long, and it’s not going to be very long before archivists and archives will need to have things pretty well figured out in terms of their position in the new reality.”
With so much publicity about deep fakes in the general media, one would think that awareness among archivists would be high. But Tariot says it really isn’t, particularly at smaller archives that have only still-image collections, or that are less well-funded and –staffed.
“I would say probably awareness is fairly low at this point,” he says, “just because the topic hasn’t been around that long, and because of the full plate that archives and archivists generally have. At some of the larger archives that I’ve spoken with, it is beginning to creep in, mostly on the still-image side, as is typical with technology cycles as they move through archives. Still images are the front line for changes, just because they’re smaller files, and easier to transmit.”
The slowness to react is surprising. The issue has been so much in the public eye. You’d have thought archivists would be on high alert.
“I guess my operating assumption,” Tariot says, “the reason for my putting all this effort into publicizing the topic, is that I don’t feel it is high enough.”
Does archivists’ slowness to take full heed of the issue suggest the danger is being overstated?
“Like any hot topic out there,” he says, “there is always the job of separating the hype from the reality. And the deep-fakes phenomenon definitely has a lot of hype associated with it. The threats are real and significant across a wide swath of politics, law enforcement, and other fields, let alone archives, licensing, and the stock footage world.” But for all that, he adds, “deep fakes aren’t yet at the stage where they represent a true threat, because they’re just not good enough.”
Still, he sees an arms race brewing that will call for greater and ongoing validation, verification, and authentication of more and more convincing “fake” images. And some battles will inevitably be lost.
“Some have compared it with robocalls and spam email: some will always get through but generally we can identify them and respond to them accordingly.”
He is not saying, then, that the threat is not real, and mounting – however, “we’re not at the point where they’ve been truly weaponized. It will be an ongoing process of trying to identify deep fakes and deal with them accordingly.”
Tariot sees issues of both technological challenge and threats to reputations. Is material that comes into an archive authentic? Is it staying authentic when it’s in the archive? When it leaves the archive, is it being used to create new forms of media?
And what legal, ethical, and rights issues are involved?
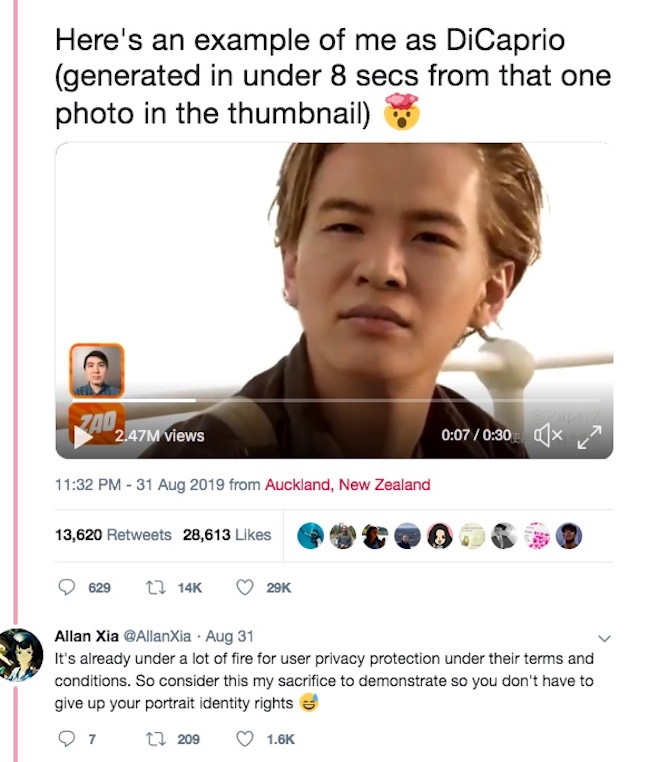 The last of those issues – rights – will be a challenge: archivists will need to “be in a position to understand and elucidate and create new models for dealing with the rights of people appearing in their content.” That’s a gatekeeper role, in the sense that archivists will need to balance defense of the rights of people depicted with helping innovators to use existing content in arguably legitimate ways: to create new forms of content “such as to insert yourself in your favorite movie.”
The last of those issues – rights – will be a challenge: archivists will need to “be in a position to understand and elucidate and create new models for dealing with the rights of people appearing in their content.” That’s a gatekeeper role, in the sense that archivists will need to balance defense of the rights of people depicted with helping innovators to use existing content in arguably legitimate ways: to create new forms of content “such as to insert yourself in your favorite movie.”
Indeed, that is the purpose of a new and rapidly popular Chinese online tool, Zao, that allows users to feed their own image into film and television clips. Users can inject just one image of themselves into software that then processes existing footage and achieves results that, while they would hardly fool any archivist, are impressive first steps in that direction.
 Advertisers have been developing such artificial-intelligence technologies, too. In one European advertisement, a synthetic Audrey Hepburn pushes a brand of chocolate bars.
Advertisers have been developing such artificial-intelligence technologies, too. In one European advertisement, a synthetic Audrey Hepburn pushes a brand of chocolate bars.
“There’s always going to be a pitching pendulum in terms of how rights and enforcement of rights get adopted and responded to,” Tariot suggests.
Are archives facing a torrid future, as such technologies advance? Will evermore technologically savvy archivists be needed, one also equipped with awareness of how copyright and other concepts are shifting?
“Yes and no,” Tariot says. “Archives have always had to deal with fakes, forgeries, misrepresented content… This is really nothing new. There are some new wrinkles to it, but when you boil it down to its essence, this is not something that archivists aren’t trained to respond to.”
But presumably the challenges will be greater if the faking of images becomes more common, and more sophisticated? And more weaponized. One can imagine political campaigns having to hire archivists to deal with it. So, too, presumably, will human-rights organizations and their opponents who often depend on film footage to make a case that abuses have or have not taken place.
The human-rights issue already arises in a slightly different way with police body-cam footage. Grainy, low-res, at an odd frame rate, it already looks synthetic. Its technical irregularities could make it particularly vulnerable to abuse, just as it already is subject to misinterpretation — it often is used to confirm the prejudices that predated it.
Like “democratizing” tools such as the Chinese program, Zao, body cams are part of a vast, multifaceted wave of video technologies that all multiply the kinds and volume of footage that archives and archivists could and really should be asked to handle. But even without a welling up in the amount of image data being produced and archived, archives have always been stretched thin in personpower and funds to do their jobs.
One deepfake-related concern for archives, Tariot says, is that they will have to decide whether to allow their holdings to be used to “train” their deepfake and similar software programs. The developers will be looking for vast stores of images with which to improve the sophistication of their AI-shaped-image programs.
“Archives are going to be the repositories that synthetic media creators are going to go to, because they need all of this training material,” Tariot explains. “The more of that you can put into the neural network, the better your new synthetic media will be. So if you want to swap Albert Einstein’s face onto Charlie Chaplin’s body, you want lots and lots of shots of Einstein’s face, and you want lots and lots of shots of Chaplin’s body. This will allow you to create a higher and higher quality deepfake, and the only way you can do that is by accessing an archive” — unless, he says, developers can in the emerging future find other ways to gather up usable images. He notes, for example, that deepfake programs already have code with which “you can run it and it will scrape all of YouTube, and get what it can.”
YouTube and its ilk provide plenty of footage of your Albert Einsteins and Charlie Chaplins. And developers and all those democratic users aren’t likely to pay much heed to whether or not helping themselves to such material is technically legal, or not. Says Tariot: “It’s a frontier mindset out there and your rights really only truly exist insofar as you have the ability to exert them.”
However such issues shake out, he has no doubt that archives will continue to have a role to play in the emergence and management of deepfakes and other altered images like them. “Archives are in a unique position in that they are the gatekeepers for the content that is going to make this all turn as a wheel,” he says. Among the issues they will contend with is that so much of their content ends up online, whether or not they means it to. (Software programs increasingly are able to overcome low-resolution challenges of the kind posed by online leaked or illegally posted content.)
What does all this add up to, in terms of what archives will need to be able to manage, in the coming years?
Successful archivists, Tariot believes, will need to “understand the legal landscape, understand the rights landscape, recognize the threats and opportunities, and generate user technology to generate new content, new markets, and foster relationships with the creators of this new content.”
 To help them deal with deepfakes and similar phenomena, new tools and processes will emerge, he has no doubt. To aid with the demands for verification, authentication, and validation, those will likely be built into work flows “so it doesn’t have to be managed at a granular level by archivists.”
To help them deal with deepfakes and similar phenomena, new tools and processes will emerge, he has no doubt. To aid with the demands for verification, authentication, and validation, those will likely be built into work flows “so it doesn’t have to be managed at a granular level by archivists.”
What kind of new tools?
For example, he says, “as soon as you take a picture, it will be given an encrypted key value that will be virtually unbreakable, stored on a shared ledger, worldwide, so verification can be done in the cloud as opposed to at a single source.”
Among leading researchers into such responses is University of California at Berkeley’s Hany Farid, who is developing a deepfake detection system.
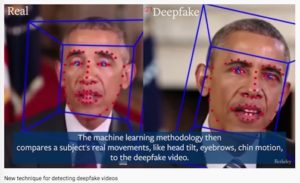 Such processes could be automated, and built in, and successful archivists will know how to use them dependably.
Such processes could be automated, and built in, and successful archivists will know how to use them dependably.
That’s a relatively optimistic view, isn’t it?
“Right,” Tariot agrees. The threats and challenges are real, he says, but “that does get overblown and I try to balance things out.”
“There are,” he says, “tools that are being developed that are going to do a good job of identifying deepfakes.”
Related Posts:





Previous Post: NFPF Awards Grants to 35 Institutions